
SQL Uma abordagem para bancos de dados Oracle
Eduardo Gonçalves

SQL: Uma abordagem para bancos de dados Oracle
Agradecimentos
Em primeiro lugar, agradeço a Deus por este presente que é a minha vida e por mais esta conquista. Dedico este livro a minha esposa Thais e a minha filha Lisyê. Vocês são meus tesouros. Obrigado por entender as ausências, cujo motivo, foi às incontáveis horas despendidas para que este projeto fosse possível. E por último, não menos importante, agradeço aos meus pais por tudo que sempre fizeram e continuam fazendo por mim. Amo todos vocês.
Sobre o autor
Formado em Tecnologia da Informação, possui mais de 10 anos de experiência em análise e desenvolvimentos de sistema voltados á tecnologias Oracle, trabalhando em grandes empresas como Lojas Renner, Mundial S.A, Tigre S.A, Pernambucanas, Tractebel Energia, Portobello Cerâmica, Bematech, entre outros. É instrutor de cursos oficiais da Oracle – nas linguagens SQL e PL/SQL. Também atua no desenvolvimento de aplicações mobile para a plataforma iOS. Atualmente, desempenhando o papel de Líder Operacional de Projetos na Supero Tecnologia.
Prefácio
Sempre gostei de livros dos quais “conversam” com o leitor, principalmente os técnicos. Como se fosse uma troca de idéias, entre o autor e quem esta lendo. Procurei escrever desta forma, pois creio que com isto a leitura se torna mais clara e amigável, como se fosse um bate papo entre amigos, conversando sobre qualquer assunto.
Procurei colocar neste livro tudo que você vai precisar saber sobre a linguagem SQL. O livro aborda conceitos que são utilizados no dia a dia do desenvolvimento e análise de sistemas para banco de dados Oracle. Repleto de exemplos, este livro também vai ajudá-lo como fonte de referência para consulta de comandos e como utilizá-los. Tenha todos, uma ótima leitura!
Considerações
Público alvo
Este livro se destina a iniciantes e experientes na linguagem SQL. Para os iniciantes, são abordados conceitos sobre a estrutura da linguagem SQL e as características voltadas para banco de dados Oracle. Inclusive alguns conceitos do padrão ANSI, também são abordados. Para os já experientes, ele ajudará como fonte de referência e para relembrar conceitos e técnicas da linguagem.
Como está dividido o livro?
Primeiramente, são abordados conceitos sobre bancos de dados relacionais, como por exemplo, os conceitos de Relações, Tabelas, Linhas, Colunas, Registros, Integridade de Dados, bem como aspectos relacionados à Linguagem SQL, como sua definição e suas três estruturas – Linguagem de Definição dos Dados (DDL), Linguagem de Manipulação dos Dados (DML) e Linguagem de Controle dos Dados (DCL).
Depois desta introdução, são abordados e detalhados todos os aspectos da linguagem SQL no âmbito prático, onde é mostrada cada uma de suas estruturas, seus comandos e características. Sempre apresentando explicações para cada conceito ou comando e, em seguida, demonstrando aplicações através de exemplos.
Contatos
Para falar com o autor, envie email para eduardogoncalves.br@gmail.com.
Sumário
- 1 - No início... Era o caos!
- 1.1 - Por que ler este livro
- 2 - Banco de dados
- 2.1 - Introdução ao banco de dados relacional
- 2.2 - Chave primária (índice primário)
- 2.3 - Chave estrangeira
- 2.4 - Chave alternativa
- 2.5 - Integridade de entidade
- 2.6 - Integridade referencial
- 3 - Introdução à linguagem SQL
- 3.1 - Oracle Corporation e Banco de dados Oracle
- 3.2 - Comunicando com o banco de dados Oracle
- 3.3 - Escopo do usuário
- 3.4 - Transações
- 3.5 - Dicionário de dados do Oracle
- 3.6 - Como o Oracle executa comandos SQL
- 4 - Executando comandos SQL com SQL*Plus
- 4.1 - O que é SQL*Plus?
- 4.2 - Comandos de edição do SQL*Plus
- 4.3 - Variáveis de sistema
- 4.4 - Definindo Variáveis no SQL*Plus
- 4.5 - Configurações iniciais de login do SQL*Plus
- 4.6 - Verificando Variáveis de Substituição no SQL*Plus
- 4.7 - Automatizar login do SQL*Plus
- 5 - Limites do SGDB Oracle
- 5.1 - Tipos de dados do SGDB Oracle
- 5.2 - Resumo
- 6 - Gerenciando usuários
- 6.1 - Manipulando usuários
- 6.2 - Concedendo acesso ao usuário
- 6.3 - Privilégios de sistema
- 6.4 - Acesso através de ROLES
- 7 - Manipulação de tabelas
- 7.1 - Manipulando Tabelas
- 7.2 - ALTER TABLE
- 7.3 - DROP TABLE
- 7.4 - TRUNCATE TABLE
- 7.5 - Ordenando dados
- 7.6 - Trazendo dados distintos
- 7.7 - Relacionamento entre tabelas
- 7.8 - INNER JOIN
- 7.9 - Cláusula USING
- 8 - Selecionando dados
- 8.1 - Selecionando dados
- 8.2 - SELECT FOR UPDATE
- 8.3 - Selecionando o destino
- 8.4 - Restringindo dados
- 8.5 - Escolhendo linhas e colunas
- 8.6 - Utilizando operadores
- 9 - Manipulação de dados
- 9.1 - Inserção de dados
- 9.2 - Atualização de dados
- 9.3 - Exclusão de dados
- 10 - Trabalhando com funções
- 10.1 - Funções de caracteres, de cálculos e operadores aritméticos
- 10.2 - Funções de agregação (grupo)
- 10.3 - Funções de data
- 10.4 - Funções de conversão
- 10.5 - Funções condicionais
- 11 - Integridade de dados e integridade referencial
- 11.1 - Integridade de dados e integridade referencial
- 12 - Oracle avançado
- 12.1 - Trabalhando com views
- 12.2 - Trabalhando com índices
- 12.3 - Sinônimos
- 12.4 - SEQUENCES
- 13 - Anexos
- 14 - Referências Bibliográficas
No início... Era o caos!
1.1 - Porque ler este livro
Antes de iniciarmos com as abordagens de banco de dados e SQL vamos entender quais foram às motivações que levaram ao desenvolvimento destas tecnologias e como isso melhorou muito a forma de desenvolver sistemas, criando softwares mais robustos e confiáveis.
Houve um tempo onde não existia o conceito de banco de dados, muito menos sistemas gerenciadores para este fim. Mas então, como os dados eram armazenados? Pois bem, neste tempo os dados eram armazenados em arquivos, como por exemplo, planilhas ou arquivos de texto, que ficavam gravados nos computadores dos usuários ou em fitas e disquetes. Na época isso já era uma evolução em tanto, contudo, mesmo as informações estando armazenadas em meios digitais, havia falhas e isso ocasionava muitos problemas.
Muitos dos problemas estavam relacionados a duplicidade de dados e inconsistências de informações. Sem falar nos problemas de falhas dos arquivos, onde os mesmos, por alguma razão acabavam corrompidos e todas as informações eram perdidas. Muitas vezes estas informações ficavam guardadas em disquetes ou fitas que se perdiam ao longo do tempo ou se degradavam pelo mau uso.
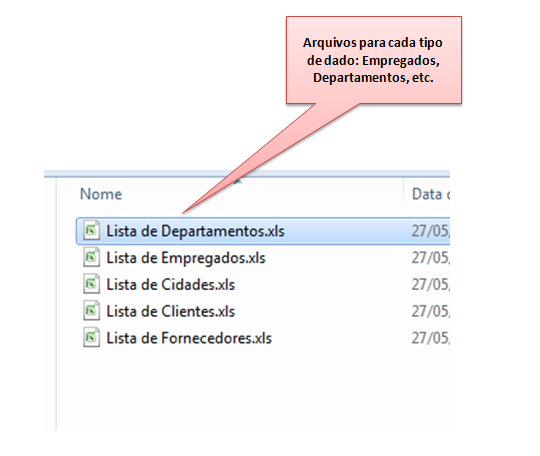
Outra dificuldade era que as informações não se relacionavam, ou seja, não existia uma ligação entre elas, e com isto, pouco poderia ser feito para utilizá-las como fonte estratégica de negócio numa empresa, por exemplo. Era muito complicado cruzar informações de diversas áreas de negócio e consolidá-las a fim de medir a produtividade de uma empresa ou usá-las em tomadas de decisão. Para que você possa entender o que estou falando, vamos observar os casos a seguir.
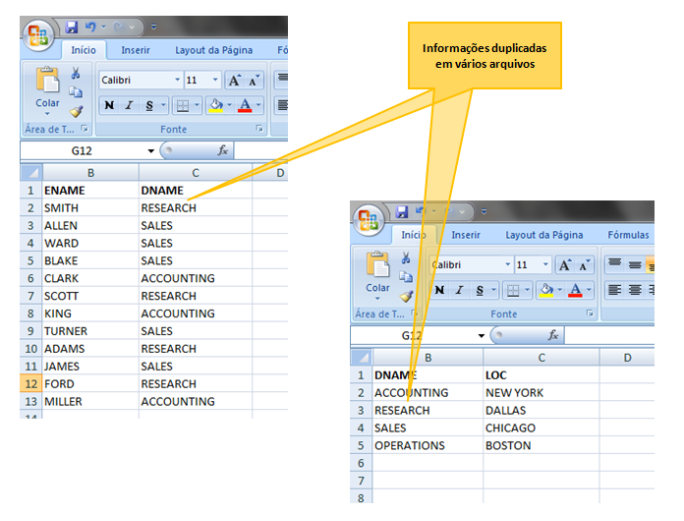
Observando a figura anterior, vemos um problema clássico no uso desta abordagem, a duplicidade de dados. Nele vemos que existem duas planilhas, uma com a lista de empregados e outra com a lista de departamentos. Além das informações estarem em planilhas independentes, não possuindo assim, referencia uma com a outra, é possível constatar a duplicidade de dados, onde o nome do departamento, neste caso, representado pela coluna DNAME, aparece nas duas listas. Isto era um problema, pois a duplicidade de dados, além de resultar em maior espaço em disco, abre margem para outro problema que era a inconsistências de dados, conforme pode ser visto no próximo exemplo.
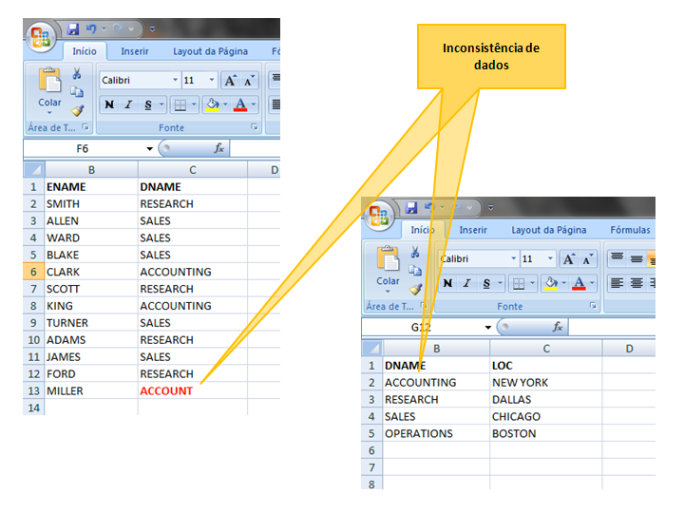
Voltando as mesmas listas anteriores, a de empregados e departamentos, podemos observar que a escrita referente ao departamento ACCOUNTING (Contabilidade) na planilha de empregados foi escrito de forma incorreta, sendo digitado como ACCOUNT. Com isto, aumentam-se as chances do surgimento de dados inconsistentes e não confiáveis, onde temos duas descrições diferentes, mas que querem dizer a mesma coisa.
Outra forma de armazenamento de dados em arquivos era o famoso “tabelão”, onde as informações de diferentes tipos eram gravadas todas num único arquivo. Veja o exemplo a seguir.
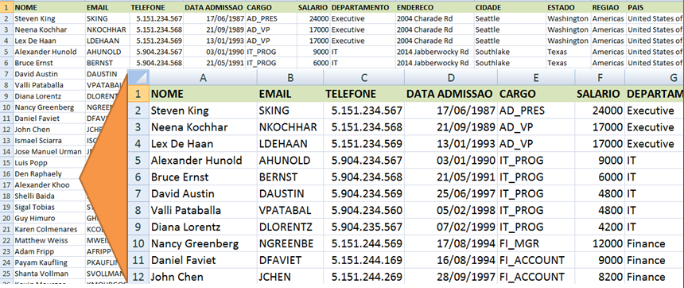
Note que todos os dados referentes aos empregados, como, nome, departamento, cargo, etc. estão todos em um mesmo arquivo. Com isto, vemos muitas informações sendo duplicadas em um arquivo inchado, onde os riscos de inconsistência são enormes, pois a mesma informação que aparece em vários lugares, por exemplo, podem conter descrições diferentes por conta de erros de digitação. Sem falar, quando uma informação muda, como, por exemplo, um nome de departamento ou de um cargo, é necessário verificar todas as linhas onde esta informação aparece para alterá-las de forma igual. Além do retrabalho, pode ocorrer, por esquecimento de quem está atualizando, que linhas que não sejam alteradas com a nova informação, gerem dados conflitantes e sem nexo.
Creio que você pode ter uma idéia de como as coisas eram antes de existirem sistemas de gerenciamento de dados, cujo objetivo era justamente possibilitar um ambiente consistente e organizado, o que não acontecia no passado. Foi assim, para que estes e outros problemas fossem resolvidos, que surgiram os bancos de dados e seus gerenciadores. Com uma implementação baseada em técnicas de modelagem de dados e com uma linguagem robusta de acesso, foi possível criar um ambiente seguro, confiável e de alto desempenho e processamento para a manipulação e armazenagem dos dados.
Além de manter todos os dados num único lugar, de forma centralizada, através da modelagem de dados foi possível levar o conceito de administração de dados para um nível mais alto, diria até um existencial, muito melhor e muito mais organizado. Através das regras de normalização de dados, a chamadas Formas Normais, é possível modelar toda estrutura de dados de um sistema, visando a organização, o desempenho e principalmente a flexibilidade e a clareza. Quando modelamos um sistema, não apenas criamos a base de dados a satisfazer apenas o intuito de armazenamento, mas sim, avaliamos qual a melhor de fazer isto. Para exemplificar, veja como ficar o exemplo anterior, utilizando os dados de Empregados e Departamentos.
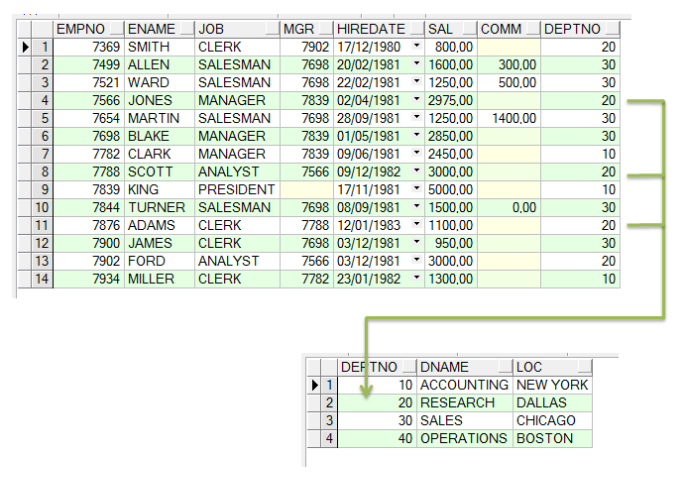
Não vamos aqui, nos aprofundar nos conceitos de modelagem de dados, entrando nos meandros de cada Forma Normal, por exemplo, nem nas demais técnicas, mas seguindo este exemplo simples, é possível demonstrar como podemos estruturar estas duas fontes de dados de forma clara e organizada. Note que nesta ultima figura tempos o que podemos chamar de duas tabelas, uma de dados de empregados, onde temos informações sobre nomes (ENAME), cargos (JOB), salários (SAL) e outra de dados de departamento, onde temos informações com nomes (DNAME) e localizações (LOC). Veja que embora sejam duas fontes de dados distintas existe uma ligação entre elas. Esta ligação está sendo feita através de uma das colunas, a coluna DEPTNO. Veja que esta coluna existe nas duas tabelas. Este que parece ser um pequeno detalhe faz com que nossas fontes sejam consistentes e estejam dentro das regras de modelagem. Observe como ligamos vários empregados a departamento, sem repetir as informações, utilizando um código. Com isto, se necessitarmos alterar alguma informação relacionada a um determinado departamento, como, por exemplo, o nome ou sua localização, não precisamos alterar para cada empregado, alteramos apenas o departamento em questão, na tabela de departamentos. Desta forma, conseguimos manter as informações de forma consistente, sem duplicidades, e desta forma também dispostos de forma estruturada.
É obvio que este foi um exemplo simples, como já mencionado, contudo, serve para mostrar que com o advento dos bancos de dados estas e outras técnicas podem ser utilizadas na criação de sistemas capazes de atender as demandas mais complexas ou que exigem maior processamento e alta performance. Além do mais, o banco de dados permite a possibilidade de criarmos um ambiente único onde todas as fontes de dados coexistam nele. Desta forma, deixamos de ter arquivos distintos, em localizações diferentes e que não possuem uma ligação lógica, nem mesmo física.
Agora que você já entendeu como era no início, está na hora de entender o agora, como funcionando os bancos de dados e seus gerenciadores. Entender seus conceitos e como trabalham. Além disso, aprender como é feita a comunicação com estes bancos e com os dados armazenados neles.
Dados do produto
- Número de páginas:
- 349
- ISBN:
- 978-85-5519-055-1
- Data publicação:
- 11/2014


